
A la base, un enjeu de passage à l’échelle
Dans notre entreprise, éditeur de logiciel, notre nombre de clients augmente chaque jour (bonne nouvelle!) et nous sommes donc face au challenge perpétuel d’assurer la même qualité de support aux clients sans pour autant augmenter de façon linéaire la taille de nos équipes.
C’est un problème de scalabilité (mise à l’échelle) classique chez nombres d’équipes Tech représenté par ce schéma:
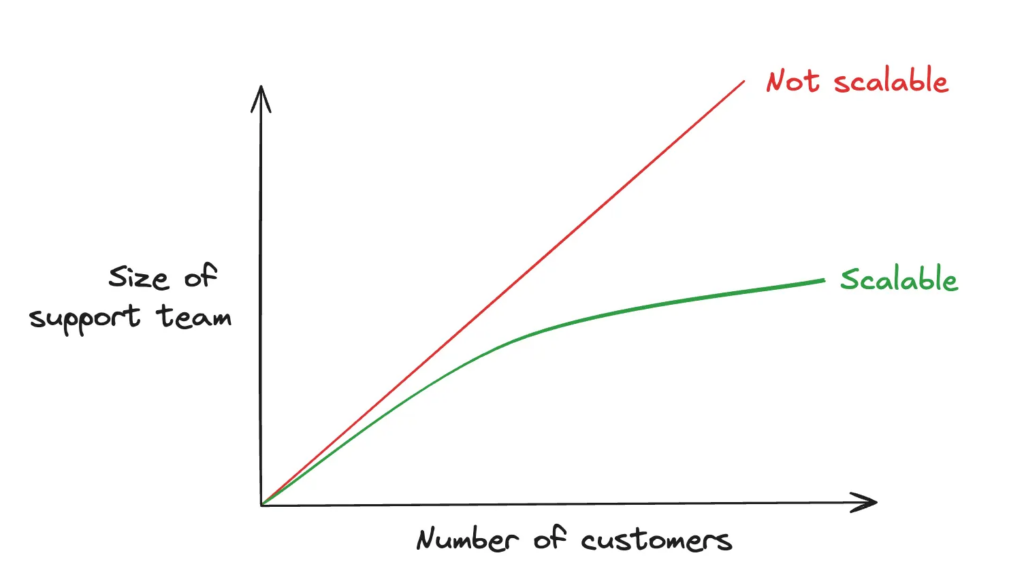
Convaincu qu’une grande partie des problèmes remontés par les utilisateurs sont récurrents même s’ils ne sont pas exprimés de la même façon par tous les utilisateurs, je propose aux équipes de tester une IA avec nos propres données terrain pour accélérer les réponses apportées aux utilisateurs. Après quelques semaines d’expérimentation, pas de grande révolutions ou d’effet waow, mais indéniablement du temps gagné sur certains tickets – des petits progrès, pas à pas avec un impact significatif sur notre performance, illustrés par ces mesures:
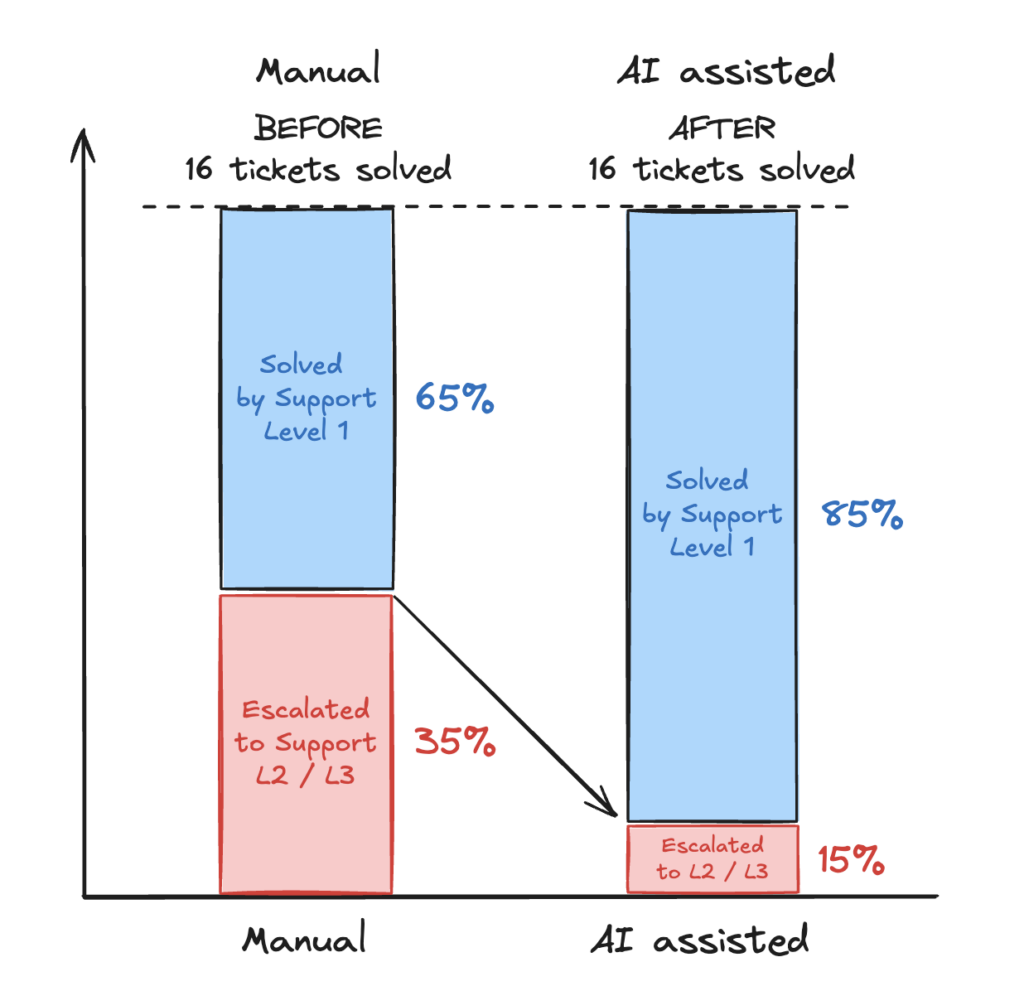
- au Support de 1er niveau: 4 tickets sur 16 ne sont plus escaladés mais directement pris en charge par les équipes au Niveau 1 grâce aux réponses apportées par l’IA
- au Support technique dit de 2ème et 3ème niveau: entre 4 et 5h gagnées par semaine et par personne sur la résolution des problèmes les plus complexes avec l’aide des diagnostics proposés par l’IA
La productivité de l’équipe s’améliore: certains tickets sont corrigés en quelques minutes au lieu de quelques heures. Une partie du travail fastidieux de recherche dans l’historique est facilité, ce qui permet aux personnes de dégager du temps pour aller corriger davantage les causes racines.
Voyons maintenant comment nous sommes arrivés à ces résultats qui sont très probablement largement reproductibles dans la plupart des organisations.
La résolution manuelle des demandes clients
Voici globalement le process simplifié de notre support client: les problèmes sont remontés soit par nos clients (Customer request), soit via nos sondes de supervision (System failure).
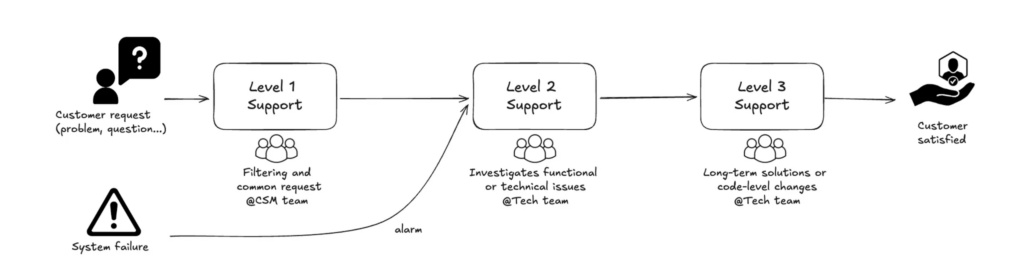
Chaque jour l’équipe résout au plus vite les problèmes rencontrés: API indisponible, problème réseau, tentative d’attaque, problème de certificat, saturation mémoire sur traitements par lots, deadlocks sur la BD… Parfois, l’équipe a le temps de s’attaquer à la cause racine, parfois, prise par l’urgence et le volume de tickets, elle se contente de relancer le service (réparation) sans analyser la cause réelle. Dans ce dernier cas, le problème va très certainement revenir.
Voyons maintenant comment l’arrivée de l’IA et particulièrement de l’approche RAG a ouvert de nouvelles possibilités.
Choisir une IA RAG pour accélérer la résolution de problème
Une IA RAG est une IA type LLM classique (ChatGPT, Claude, Mistral…) à laquelle on ajoute un corpus de nos données propres afin de la spécialiser pour des analyses prenant en compte nos spécificités.
https://en.wikipedia.org/wiki/Retrieval-augmented_generation
Voici quelque solutions disponibles en décembre 2025:
- ChatGPT → Projects
- ClaudeAI → Projects
- Google → NotebookLM
- …
Nous sommes partis sur NotebookLM Pro car il est inclus dans notre licence Google globale et surtout par simplicité de mise en oeuvre no code. Peu après, nous avons également reproduit le même prototype avec ChatGPT Plus en s’appuyant sur les Projects. Bien entendu, les plus aguerris peuvent construire et entraîner “from scratch” à partir de modèles “vides” ou encore d’Agentic mais cela requiert des compétences plus pointues.
Voyons maintenant les étapes pour construire le corpus de données et entrainer l’IA sur nos sources en 3 étapes:
- Identifier les sources de données le long du process
- Collecter les données
- Charger les données dans l’IA
Préparation de l’IA sur nos données terrain
1 – Identifier les sources de données spécifiques
La première étape consiste à identifier le corpus des données manipulées par les équipes lors de la résolution des incidents en 2 étapes:
- observer le process de bout en bout
- noter les données produites par les outils utilisés
Dans mon cas, voici une version simplifiée du process de bout en bout et des données produites:
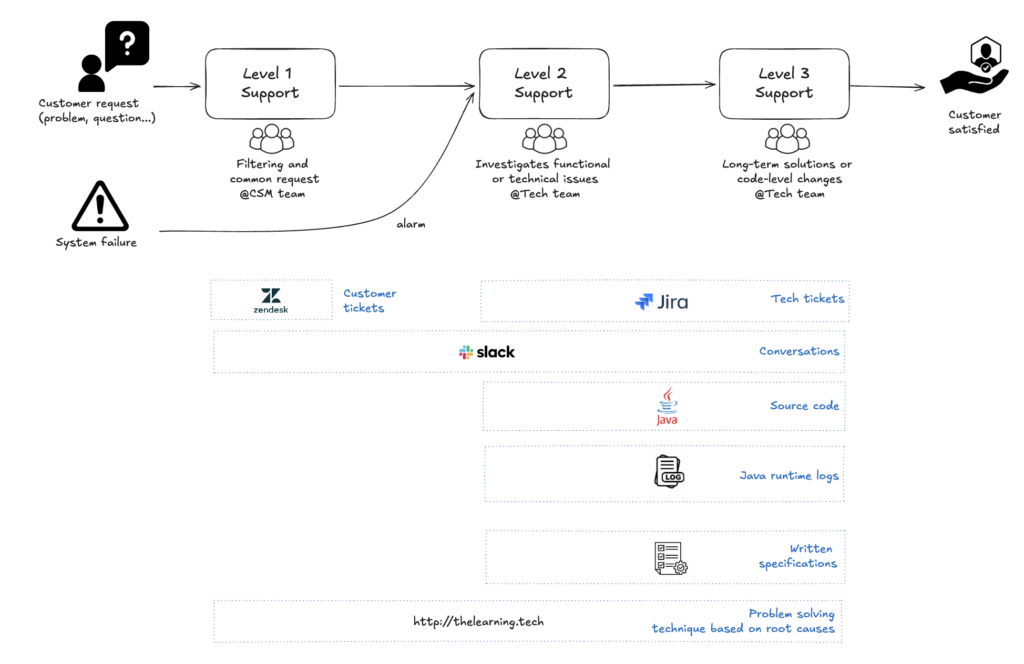
2 – Exporter les données
L’étape suivante consiste à exporter l’ensemble des données produites (tickets Zendesk, Jira, documents Office…) dans des formats compréhensibles par l’IA (PDF, TXT, CSV, JSON, JPG, URL…).
La plupart des outils comme Jira, Notion, Slack… proposent des fonctionnalités d’export permettant de récupérer la totalité des champs. Pour ma part, j’ai exporté les informations contenues pour une partie des tickets (clients) en prenant soin d’anonymiser certaines données. Pour Zendesk, il n’y a pas de fonctionnalité d’export via les menus : il est donc nécessaire de passer par un script python pour utiliser l’API d’export.
Dans mon cas, j’avais également chargé mon propre article de blog sur la résolution de problème, ce qui a permis par la suite de s’assurer de l’analyse rigoureuse via la technique de recherche de causes racines.
⚠️ Il se pose bien entendu la question de la confidentialité des données importées. Aussi je vous encourage à valider ce type de d’expérimentation en interne dans votre entreprise, vérifier les conditions générales de chaque IA, de privilégier les abonnements payants et d’éviter d’exporter toutes données confidentielles (credentials, données financières confidentielles, données personnelles…).
A titre d’information, pour NotebookLM:

3 – Charger les données dans l’IA RAG
Le chargement des sources est en principe un détail car il consiste en un simple upload dans l’outil.
⚠️ Les limites en taille de fichier / tokens ne sont pas toujours très simples à appréhender, ces limites sont perpétuellement revues et seront probablement obsolètes avant que cet article ne soit publié 😊.
Une fois les fichiers chargés, l’IA est maintenant entraînée sur notre propre corpus de données et en mesure de répondre à nos prompts en s’appuyant sur nos sources mais aussi sur son entrainement original (= le web).
L’IA RAG est maintenant prête à être utilisée pour différents objectifs. Voyons maintenant 3 cas d’usage où elle s’est avérée particulièrement pertinente.
Quelques cas d’usage
1er cas – Prompter pour répondre plus vite au client
Notre objectif: trouver immédiatement la réponse au problème remonté par le client via un prompt.
Lors des premiers tests réalisés avec Moustapha, développeur en charge des analyses et correctifs (Support Niveau 2 et Niveau 3), je lui demande quel est le dernier ticket un peu difficile sur lequel il a travaillé. Il s’agissait d’un problème de traitement récurrent pour un de nos grand client. On rédige donc ensemble un premier prompt:
Nous rencontrons l’incident suivant pour le client Xxx, voici un extrait des logs et la description du ticket Zendesk:
"extrait des logs"
"contenu du ticket"
Contrainte: utilise les sources de tickets fournies en respectant la démarche de résolution problème
Question 1: peux tu nous dire si cet incident s’est déjà produit dans les sources de données que nous avons chargé ?
Question 2: quelle était la cause racine de cet incident ?
Question 3: comment réparer cet incident?
En quelque secondes, la réponse est sans appel: ce problème est déjà arrivé le 14/01/2024. Les cause et les actions mises en oeuvre à l’époque sont clairement explicité (tout avait été tracé dans Zendesk / Jira à l’époque).
A la lecture de cette réponse, je me souviens du visage de Moustapha: un vrai effet Waow 😄
Moustapha: C’est exactement la correction que j’ai faite cette semaine ! Mais j’avais complètement oublié que c’était déjà arrivé le 14 janvier 2024 !
Moi: Et cela t’a pris combien de temps pour corriger ce problème cette semaine ?
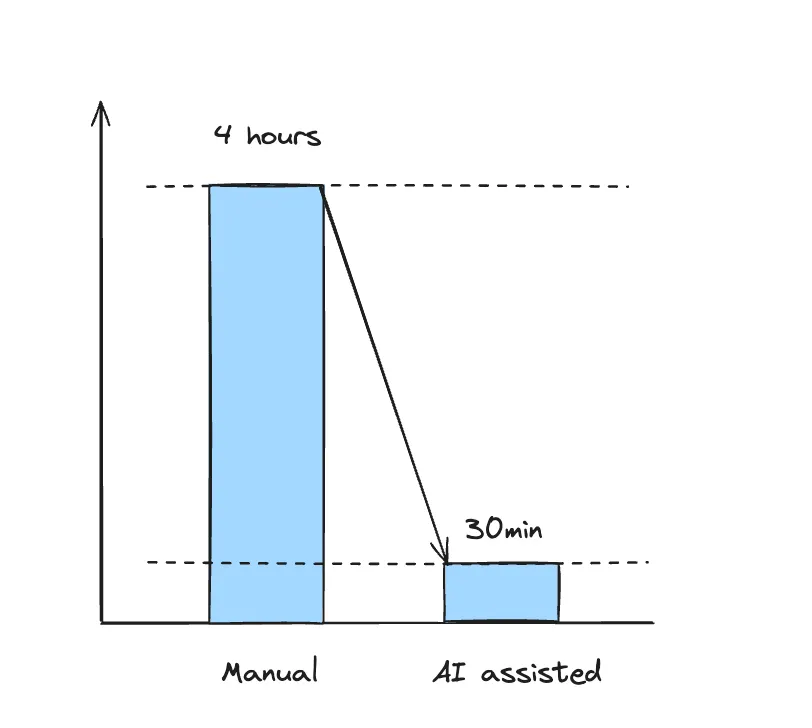
Moustapha : Au moins 4 heures 🥶
Le prototype semble prometteur et Moustapha est partant pour tester l’IA !
Après quelque semaines d’expérimentation, voici les résultats obtenus en gain de temps – environ 3 à 4h par semaine par personne :
Du côté du Support de Niveau 1, les résultats sont similaires, on gagne environ 3h par semaine par personne. Un bon démarrage étant donné la simplicité de la mise au point de l’IA RAG.
2ème cas – « Shift left » – Répondre au plus tôt au client sans escalader
Notre objectif: traiter le maximum de ticket au niveau 1 en limitant les escalades au niveau 2 et 3.
Exemple: une question complexe sur l’utilisation de notre API était traditionnellement escaladée au support niveau 2 puis niveau 3 pour arriver dans l’équipe de développement sur les spécialistes de l’API. Conséquence immédiate, on allonge le délai de réponse au client (lead time) et le développeur en charge de la réponse est interrompu (context switching) : il répond, puis reprend son travail habituel.
Grâce à notre IA RAG, on a constaté une augmentation des tickets traités directement par le niveau 1. En effet, les personnes en charge du support N1 qui ont les connaissances de base sur l’API sont maintenant en mesure d’apporter des réponses plus techniques avec l’aide de l’IA (endpoint, JSON en entrée, en sortie, trucs et astuces…) car ces infos ont déjà été abordées dans notre corpus de connaissance.
Le gain est important: environ 20% des tickets arrivant au support ne sont plus escaladés mais répondus directement par le support N1.
3ème cas – « The best service is no service! »
Objectif: proposer directement aux clients la solution en self-service via FAQ, tutoriels…
Pour réutiliser cette formule désormais célèbre « The best service is no service! » : l’idéal serait d’éviter à nos clients de contacter le support en leur fournissant toute l’aide nécessaire aux questions ou problèmes qu’ils se posent; aller jusqu’au bout du “Shift left”.
Sur ce use-case particulier, l’IA peut facilement traiter les quelques milliers de tickets de ces 2 dernières années et nous proposer des réponses aux questions les plus récurrentes FAQ, fiches d’aides aux utilisateurs…
Voici un exemple de FAQ proposée par l’IA à partir des tickets les plus récurrents que nous avons ajouté à notre FAQ utilisateur:

Les prochaines étapes
Ces premiers résultats encourageants montrent l’intêret de cette IA RAG entraînée sur nos données terrain pour nous assister sur des tâches précises et répétitives sur lesquelles notre mémoire n’est pas suffisante. Pas de révolutions, mais des progrès réguliers qui changent durablement la donne.
De plus, ce type d’expérimentation a un côté viral que nous avons constaté en interne à l’occasion des démos. En effet, avec un investissement minimum, on peut tester et voir si la pertinence est au rendez-vous. Résultat, au sein de notre entreprise une dizaine d’expérimentations sont en cours à la Tech, au Marketing, au CSM, au Professionnal Services…
Les prochaines étapes pour nous:
- automatiser les données importées dans afin d’avoir toujours les dernières données à jour: mise en place de traitement en Python pour collecter les données via API de façon incrémentale.
- utiliser les outils d’apprentissage de NotebookLM (Quizz, podcast, cartes mentales…) pour former les nouveaux arrivants et améliorer la polyvalence au sein de l’équipe
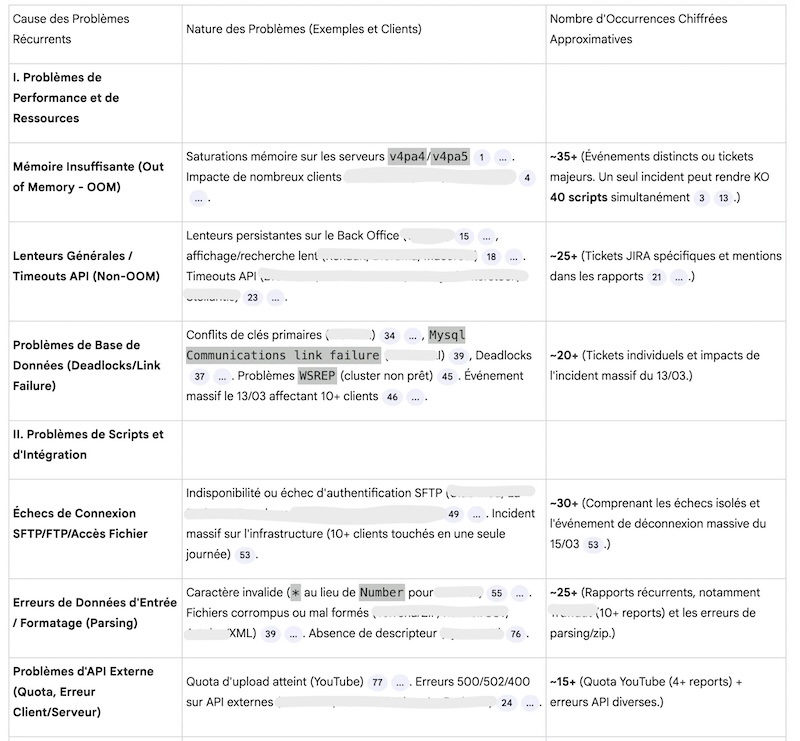
- identifier les traitements les plus incidentogènes (en application de la Loi Pareto 20% des causes provoquent 80% des problèmes):
- extraire les logs des traitements de la nuit, identifier les KO, construire, un message, envoyer le message dans les mails et dans canal slack (Agentic workflow)
- Gain: 20min / jour pour 1 personne

Et vous comment utilisez vous l’IA sur vos données propres pour accélérer les tâches répétitives de vos équipes et améliorer votre passage à l’échelle ?
Merci à Moustapha I., Céline M. et Lucas S. pour leur confiance, leur enthousiasme et leur curiosité, ingrédients indispensables au succès de ces expérimentations 💛
Laisser un commentaire