
Contexte
Après mon précédent article sur la résolution de problèmes, je vous propose une mise en pratique, tirée de mon expérience personnelle, dans le contexte d’un éditeur de logiciels. Ici les problèmes rencontrés sont des bugs (ou anomalies) à chaque livraison. Ce retour d’expérience se déroule au sein d’une équipe Scrum composée de développeurs dits intégrateurs et d’un testeur en charge de d’adapter un logiciel pour un client final. Cette personnalisation du logiciel générique est réalisée via du code Java pour qu’il réponde aux besoins spécifiques du client final.
Comme souvent, on part d’une situation peu satisfaisante et surtout assez confuse, en l’occurence ici, des livraisons en retard. Ce retard est dû au fait que l’équipe passe beaucoup de temps à corriger les anomalies, et que ce temps perdu n’est pas consacré à développer les personnalisations attendues (= features). C’est une cause apparente mais pas la cause racine, nous y reviendrons juste après. Le planning devient très tendu voire quasi-inatteignable car le retard s’accumule à chaque itération. Lorsque j’interroge l’équipe sur la façon de gérer ce retard, on me parle de problèmes de staffing: il faudrait renforcer l’équipe (le classique…), ajouter des développeurs et des testeurs pour rattraper le temps perdu.
C’est alors que j’essaie d’en savoir plus et que je pose plus de questions, notamment sur la qualité.
Au niveau de la qualité de ce qu’on livre, c’est comment ?
Réponse: … ?
Combien de défauts à corriger à chaque livraison ?
La réponse oscille entre:
Un peu / Pas mal quand même / Je ne sais pas mais c’est dans Jira !
Comme très souvent, personne n’a d’idée précise sur le nombre de problèmes de qualité (anomalies, bugs…). Je propose donc d’appliquer la démarche de résolution de problèmes à cette situation.
Plan – Première étape: bien poser le problème
Comme vous le savez maintenant, un problème est un écart et il faut donc le mesurer. Après quelques filtres et exports Jira avec l’équipe, on obtient un nombre de tickets : 27 tickets de bugs détectés en phase de test sur les 3 derniers sprints.
Bingo, nous avons notre écart et notre cible :
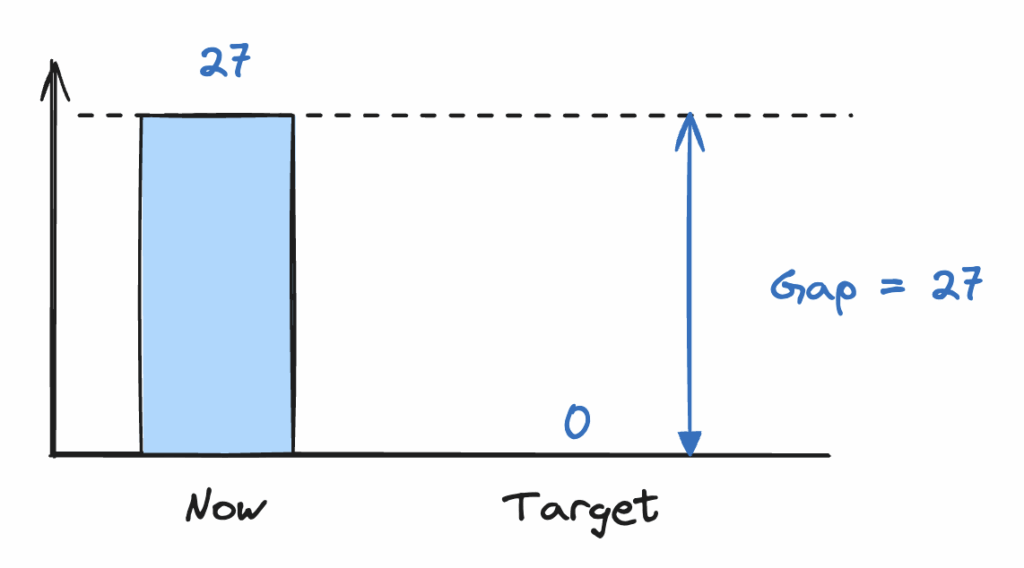
L’impact de cette non-qualité est clair: pendant que l’équipe corrige ces 27 bugs, elle se met en retard sur la livraison des paramétrages attendus pour le client.
- impact pour le client : livraison en retard du projet -> insatisfaction client
- impact pour l’entreprise éditeur : pénalités de retard -> A chiffrer
- impact pour les équipes : le testeur commence à s’agacer de la qualité des livrables qu’il trouve très insuffisante -> stress, ambiance travail dégradée
Il est recommandé de chiffrer précisément les impacts financier (calcul des indemnités de retard, perte sur la marge du projet à cause du temps passé à corriger les bugs…) même si dans cet exemple nous ne l’avons pas fait. Néanmoins on déduit, au vu des impacts relevés dans notre situation, qu’il est intéressant d’investir au moins quelques heures avec l’équipe sur ce problème de qualité.
Intéressons-nous aux causes maintenant.
Je propose à l’équipe de profiter de leur rétrospective Scrum d’une heure avec 3 développeurs et 1 testeur pour nous pencher sur le problème de façon plus précise. On analyse alors les 27 tickets préalablement imprimés. En lean, on appelle ces défauts des bacs rouges, des pièces défectueuses qu’on place dans un bac rouge afin de les analyser ultérieurement.

On regroupe ces défauts par familles de cause pour construire ce que l’on appelle un graphe Pareto afin de mettre en évidence la récurrence de certaines causes. ⚠️ Un point important à noter, on ne groupe pas par famille de bugs (bugs UI, bugs traductions, bug performance, bugs API…), on groupe par cause : donc on cherche pour chaque anomalie la ou les causes, et on compte le nombre de fois qu’elles apparaissent.
On décide alors de se focaliser sur les 4 familles de causes les plus fréquentes (= tête de Pareto):
8 occurrences de bugs produit Generic (cause #1). Le produit Generic étant développé aux USA, notre équipe d’intégrateurs n’a pas la main pour modifier le produit. Il faudra donc transmettre à ces équipes produit le ticket de demande de correctif pour qu’ils le prennent en compte lors d’une prochaine version du produit. A priori, notre équipe n’a donc pas la main pour agir sur cette cause.
6 occurrences de cas aux limites – “edge case” (cause #2). Le code développé ne résiste pas à certains cas limites. Pourquoi ? Car les développeurs ne disposent pas de tous les différents devices externes coûteux (caméra, appareil photo, empreintes digitales…). A la place ils utilisent des “mocks” sorte de bouchons de code qui émulent ces device externes. Le problème est que ces mocks ne couvrent pas les cas aux limites (env 10 codes erreurs à simuler). En revanche, la personne en charge des tests dispose de l’ensemble de ces devices et peut donc les détecter.
3 occurrences de spécifications non respectées par les développeurs (cause #3). Les développeurs avouent qu’ils ont parcouru un peu vite les spécifications en ratant quelques points clés qui étaient pourtant bien présents dans le ticket initial.
2 occurrences de spécifications ambiguës (cause #4). A la relecture des 2 derniers tickets, il s’avère effectivement que la spécification était suffisamment ambiguë pour laisser planer le doute sur ce qu’il fallait développer.
On a donc identifié nos causes racines, il est temps de passer aux contre-mesures pour améliorer la situation.
Do – Place à l’action
Je demande maintenant aux équipes ce que nous pourrions faire pour améliorer la situation sur chacune de ces causes.
Pour la cause #1 sur le produit Core, un développeur intégrateur se sent malgré tout en mesure de corriger certains bugs car il a déjà accès aux codes sources. Il propose de demander à l’équipe Core s’il pourrait être autorisé à modifier le code du produit lui-même dans la mesure où il sait comment corriger. Bien que ce soit formellement “interdit par le process”, après quelques échanges avec les n+1, n+2, n+3 au cours des semaines suivantes, on obtiendra gain de cause à la condition que les “peer review” (revues de code) soient faites par un développeur Core aux USA. Au final, cela fera gagner de nombreuses semaines aux 2 équipes supprimant une dépendance critique.
Pour la cause #2 concernant les cas limites, je demande à un des développeurs s’il a une idée.
Réponse: On pourrait ajouter 4 ou 5 nouveaux edge case dans le mock pour couvrir les 10 codes erreurs manquants.
Et ça prendrait combien de temps ?
Réponse: Environ 10min par code erreur !
🙂
Pour les cause #3 et #4 concernant les spécifications non lues ou ambigues, les développeurs, le product owner et le testeur conviennent de faire une relecture partagée avant de démarrer chaque nouvelle feature afin de lever toute ambiguité et de s’assurer que le développeur a bien compris la finalité. Le testeur propose d’ajouter systématiquement au ticket Jira l’ensemble des cas de tests qu’il va réaliser.
Le sprint suivant va être l’occasion d’expérimenter chacune de ces contre-mesures: rien de révolutionnaire mais des ajustements précis sur certains gestes et sur les passages de relais entre membres de l’équipes (product owner / développeur / testeur).
Check – Est-ce que ça marche ?
Sur le sprint suivant, tout d’abord, l’équipe se dit qu’il serait utile de suivre plus précisément le nombre de bugs et d’avoir un indicateur de performance qu’on puisse regarder tous les jours. On décide également collectivement que la qualité est l’affaire de tous. Un membre de l’équipe se charge donc de construire l’indicateur et, chaque jour, une personne différente est chargée de le mettre à jour. On en parle ensuite lors du daily meeting.
A la fin du sprint suivant, le résultat est bluffant: aucun bug remonté par le testeur ! L’équipe s’en félicite et apprécie cette première petite victoire.
Bien entendu, ce n’est qu’un début. D’autres anomalies remonteront donc lors les prochains sprints (nouvelles causes de bugs, changements de personnes…) mais l’équipe sait maintenant comment adresser chacun de ces problèmes via une approche exigeante et rigoureuse.
Act – Qu’est ce que l’équipe a appris ?
Pour l’équipe et le team leader, leur principal apprentissage a été de comprendre qu’en améliorant la qualité, on accélère le delivery. L’occasion pour eux de sortir de ce soi disant triangle Qualité / Cout / Délai dans lequel on vous demande d’en choisir 2 et de faire une croix sur le troisième. C’est faux et pourtant tellement présent dans les esprits: la réalité est qu’en améliorant la qualité, on améliore les délais et les coûts.
Pour les développeurs, c’est l’occasion de mieux comprendre le niveau d’exigence qui est attendu sur le produit qu’ils développent notamment au niveau de la robustesse du code dans les cas aux limites: une caméra débranchée brutalement, une perte de réseau… Ensuite, ils ont également pris conscience de l’importance de répondre aux attentes des clients dans les moindres détails: pas de place pour l’improvisation ou l’ambiguïté. Réussir à livrer du code bon du 1er coup n’est pas si simple, mais c’est possible : les bugs ne sont pas une fatalité !
L’équipe ira également présenter cette nouvelle pratique de la rétrospective à ses collègues dans l’open-space, une occasion de raconter et de prendre conscience du chemin parcouru.
Les pièges à éviter
- Pour vous, en tant que tech leader: éviter de pousser votre solution. Il est important de laisser les équipes proposer des idées à tester. Votre rôle est de questionner (pourquoi, comment pourrait on faire autrement), encourager et en dernier recours, si rien ne vient de l’équipe, alors proposer quelque chose à essayer.
- Eviter les silver-bullets: ”Et chez OpenAI, il parait qu’ils font…”
- Eviter les outils magiques: si un outil permettait d’éviter les bugs, tout le monde l’utiliserait.
- Attention aux experts (les “super-héros”) qui ont tendance à écraser le reste de l’équipe par leur expérience. S’ils étaient de bon coachs pour leurs collègues, la qualité serait un sujet plus important depuis bien longtemps.
Conclusion
En 1h d’application de la démarche de résolution de problème, on change drastiquement la situation en mobilisant toute l’équipe sur le sujet de la non-qualité à travers une démarche rigoureuse et pragmatique de la résolution de problème.
Cet exemple permet aussi de bousculer les points de vue un peu dogmatiques qu’on peut observer parfois: ”Tu fais du Scrum ou du Kanban / Lean (choisis ton camp 🙂) ?”. Il peut être efficace votre process de développement « maison » et d’y insérer des pratiques régulières de résolution de problèmes qui vont permettre aux équipes d’être beaucoup plus précises dans l’amélioration de la qualité. L’idéal étant de s’y intéresser dès que le problème survient.
Et vous, comment menez-vous vos rétrospectives d’amélioration continue ? Comment amenez vous vos équipes à se challenger sur la qualité du code livré pour tendre vers l’idéal du 100% Right First Time ?
Laisser un commentaire