
Pourquoi les leaders de la tech doivent être des problem solver ?
Les problèmes dans la tech, ça ne manque pas: bugs, incidents, pannes, failles de sécurité, ralentissements, incompréhensions avec les équipes produit, retards dans les projets, dette technique, …. Et les impacts sont loin d’être anodins, ils ont la plupart du temps un lien direct sur les clients (insatisfaction, risque de churn), les collaborateurs (stress) et au final l’entreprise (productivité, retard par rapport à la concurrence).
Les leaders de la tech doivent faire face à ces problèmes au quotidien avec leurs équipes. Pour autant, difficile d’avoir réponse à tout. Et surtout, il est essentiel d’impliquer tous les collaborateurs individuels dans la résolution de ces problèmes au risque de devenir soi-même le bottleneck. C’est pourquoi, les leaders tech doivent être de bons problem solver en mesure de coacher leurs équipes. Et bonus, en résolvant les problèmes, on développe aussi et surtout l’expertise des équipes.
Dans les offres de postes de leader techs figure souvent cette compétence de problem solver et c’est aussi une compétence clé selon le World Economic Forum :
« Top missing skill is complex problem solving »
World Economic Forum,2019
Dans cet article, je vous partage les clés de la démarche de résolution de problèmes en 4 étapes en suivant la démarche rigoureuse du PDCA. Cette démarche nous vient du lean management et je vous propose de l’appliquer ici au software engineering avec quelques exemples concrets. Personnellement, je la mets en pratique de façon quasi-systématique depuis une dizaine d’années maintenant et tout en coachant mes équipes à cette façon de réfléchir.
Notre cerveau nous joue des tours
Pour commencer, jetons un oeil à la façon de résoudre les problèmes selon les pays. Vous êtes nombreux à connaitre cette illustration caricaturale, je vous invite à regarder les différentes étapes :
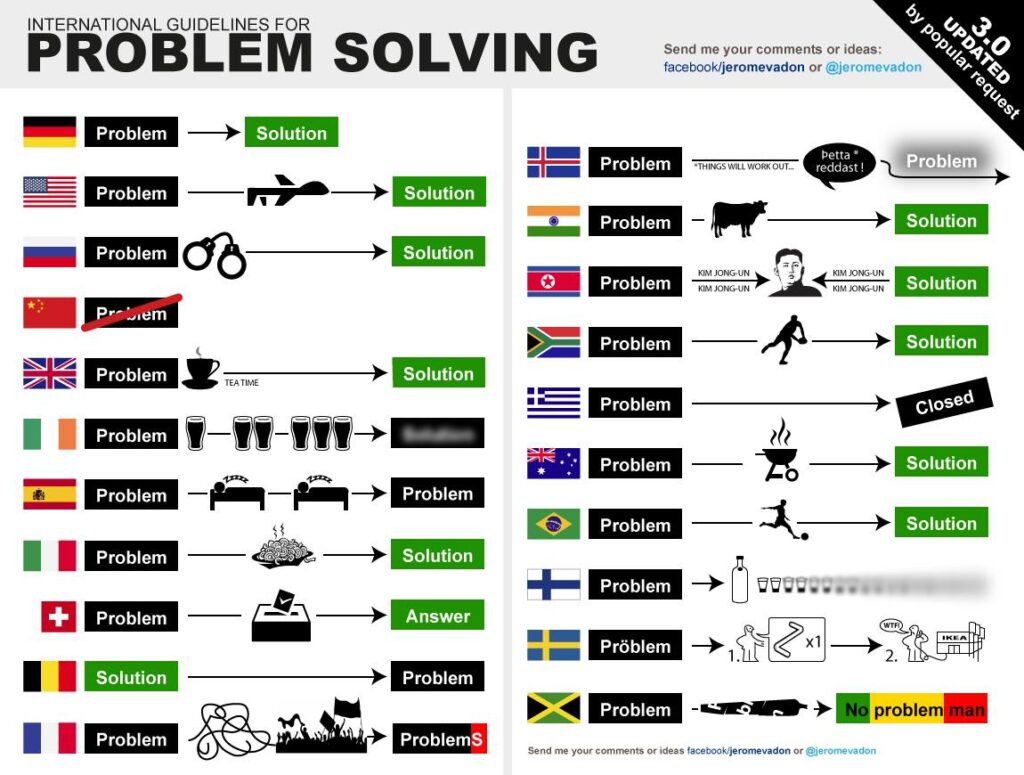
(c) Jérôme Vadon – https://www.facebook.com/jeromevadon
Que remarquez vous ?
Au-delà de son aspect humoristique, dans quasiment tous les pays, on passe toujours d’un problème à une solution.
Cette démarche arrange bien notre cerveau qui a tendance à se jeter sur les solutions prêtes à l’emploi plutôt que réfléchir vraiment à la cause de notre problème spécifique à résoudre. C’est ce que l’on appelle les biais cognitifs, des raccourcis que prend notre cerveau pour ne pas consommer trop d’énergie.
Illustrons ces biais par un exemple de la vie de tous les jours hors contexte professionnel:
si mon problème est que j’ai le sentiment d’être en surpoids, mon cerveau peut me jouer un tour (biais) et me recommander d’arrêter de manger du fromage par exemple. Est ce que ça va marcher ?
Peut-être… peut-être un peu, peut être pas du tout…
Dans cet exemple, on est exactement dans le schéma: Problème → Solution
Et pour revenir à l’IT, imaginons qu’on ait livré une nouvelle version contenant encore de nombreux bugs et défauts découverts tardivement par les utilisateurs. On pose la question:
Que faire pour améliorer la qualité de nos livraisons et éviter ces bugs ?
J’entends fréquemment:
Il faudrait plus de tests ! On pourrait avoir une personne de plus aux tests car ils ont laissé plein de bugs !
A nouveau, notre cerveau nous joue des tours: Problème → Solution
Pour démonter ce biais, prenons l’exemple de la construction dans le bâtiment.
Imaginons que nous sommes une équipe de maçons et que nous construisons des murs pour un bâtiment. Malheureusement, certains murs ont des défauts: pas droits, des trous… Les clients s’en rendent compte et demandent des retouches.
Si on applique le même type de solution que précédemment, alors il faudrait avoir davantage de personnes pour faire le contrôle qualité des murs construits ?
Là tout à coup, c’est une évidence: Non évidemment ! Il faut plutôt que les maçons apprennent à faire des murs correctement !
Alors voyons comment on peut apprendre à résoudre vraiment les problèmes et construire des murs droits 🙂
La démarche scientifique de résolution de problèmes
La démarche rigoureuse de résolution de problèmes est directement issue de la démarche scientifique (au Siècle des Lumières). Elle a été popularisée dans le monde de l’industrie après la seconde guerre mondiale par le célèbre ingénieur américain Edward Deming sous le terme de PDCA (Plan Do Check Act). Il est connu comme l’un des gourous de l’amélioration continue avec sa célèbre roue:
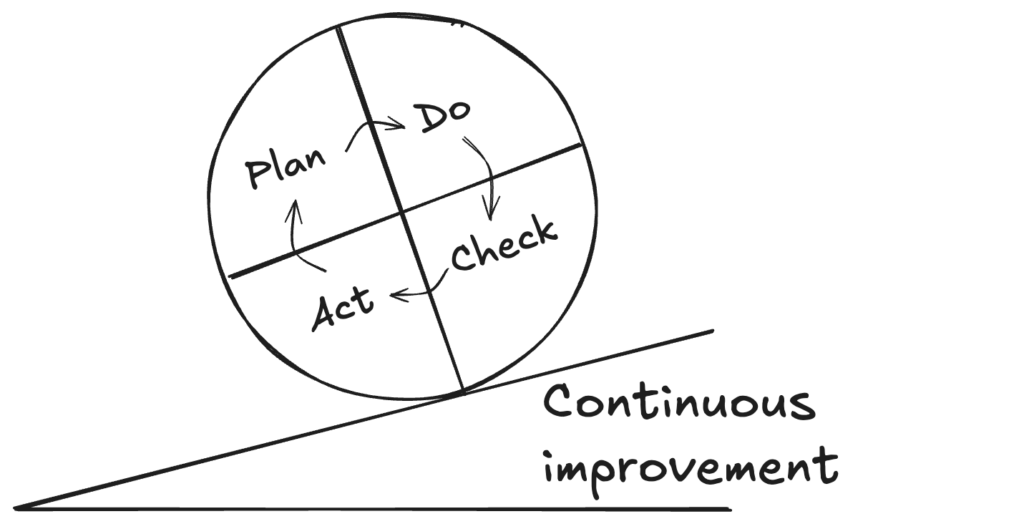
Voyons comme se déroule une résolution de problème en suivant ces 4 étapes:
- Plan: comprendre le problème
- Do: tester des contre-mesures,
- Check: vérifier l’amélioration,
- Act: ancrer l’apprentissage.
Etape 1 – PLAN: Bien poser le problème
L’étape du “plan” n’est pas du tout le moment de parler Planning mais de bien poser le problème à résoudre. C’est la partie la plus longue de la résolution de problème, qui consiste à :
- poser le problème sous forme d’un écart,
- regarder les impacts,
- identifier les causes racines.
Mais commençons par le début: qu’est ce qu’un problème ?
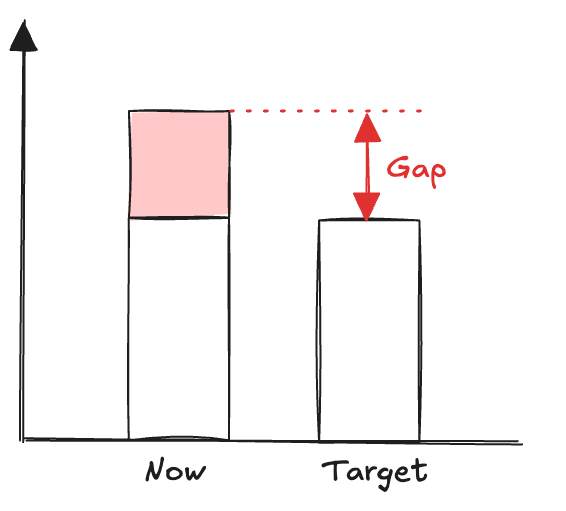
Un problème est un écart entre la situation actuelle et une situation souhaitée.
PLAN – Poser l’écart
Visuellement, il est utile de le représenter de cette façon pour clarifier le problème:
Exemples:
| ❌ Pas un problème mais plutôt une opinion | ✅ Problème |
|---|---|
| Il y a tout le temps des bugs | 27 bugs détectés en recette lors de la dernière livraison |
| Dans l’IT, vous êtes tout le temps en retard | Sur les 3 derniers mois: 3 features livrées avec 1 semaine de retard |
| La plateforme, elle est super instable | Sur le mois de juin: – 3 incidents majeurs – 6 incidents mineurs |
Comme me le rappelle souvent l’excellent Cecil Dijoux, la résolution de problème permet de sortir du monde des opinions et d’aller sur les faits.
Ok, un problème est donc un écart mesurable et pas une opinion, c’est un bon début!
PLAN – Mesurer les impacts
Maintenant, comment évaluer l’importance de ce problème ?
Pour cela, intéressons nous aux impacts c’est à dire les conséquences de cet écart ?
Pour nous aider à mesurer ces conséquences, je regarde les impacts sous 3 angles:
- Impacts pour le client
- Impacts pour l’entreprise
- Impacts pour l’équipe
Prenons un exemple concret pour illustrer cela dans l’édition logicielle:
Ecart = environ 3 à 5 sec pour afficher la home page du site au lieu de 500ms attendus
Impacts clients 😕
- 2 clients ont churn sur les 6 derniers mois en raison des performances globales et notamment de la home page.
- Les clients ne sont pas satisfaits des performances de la home page globalement (mesure satisfaction NPS remontée dans 40% des retours).
Impact entreprise 💸
- Perte de client = 25 kE revenu récurrent cette année
- Difficulté à vendre en raison des performances lors des démos
Impact sur les équipes 😠 😤
- Les développeurs rejettent la faute sur les Ops en accusant une plateforme sous-dimensionnée, et les Ops disent que les pages développées ne sont pas optimisées. L’ambiance est mauvaise, et au final rien n’avance pour améliorer les performances pour les clients.
Conclusion: on est face à un véritable problème pour toute l’entreprise et cela vaut la peine de se poser un peu pour comprendre les vraies causes et les adresser.
PLAN – Trouver les causes racines
Et maintenant, nous arrivons au coeur de la démarche, la recherche des causes… et surtout des causes racines.

Un peu à la façon d’un détective, on formule tout d’abord des hypothèses de cause à la recherche de la ou des causes racines. Une fois ces hypothèses formulées, une seule solution : aller sur le terrain avec les personnes directement impliquées afin de regarder le code, les logs, les tickets… Et l’outil magique ici pour dépasser les causes apparentes et identifier les causes racines, c’est le mot “pourquoi”.
Pourquoi le serveur a planté ? Pourquoi les TUs ont cassé ? Pourquoi ce null pointer ? Pourquoi ce Out of memory… ?
Mais dans la plupart des cas, la première réponse ne sera pas suffisante. Il faudra poser plusieurs fois la même question pour dépasser la cause apparente et arriver à la cause racine. Voici un exemple pour illustrer ce raisonnement:
Imaginons que notre applicatif favori soit arrêté de façon anormale, un “crash applicatif”.
Moi: Pourquoi est ce que l’appli a crashé ?
Ops: Parce que le file system est plein.
Moi: Pourquoi ?
Ops: Euh, attends je regarde. Ah oui, effectivement, il y a plein de logs applicatifs dans le dossier /logs.
Moi: Pourquoi ?
Ops: On dirait qu’il n’y a plus de purge, je regarde la dernière exécution. Ah oui effectivement, ça fait plus d’une semaine… Bizarre ?
Moi: Pourquoi ?
Ops: Attends, je demande à un dév… Effectivement, ils ont trouvé une régression dans la dernière livraison du batch de purge. Ça ne purge plus...
Moi: Pourquoi ?
Ops: Ils disent que dans un edge case (exception), on ferme mal la transaction en base données et ça plante le batch.
Ca y est, on a ENFIN la cause racine: une erreur dans le code sur une gestion d’exception qui provoque une erreur en BD : transaction restée ouverte. En général, après 5 « pourquoi » (la règle des 5 pourquoi) on arrive sur la cause racine qui correspond très souvent à 2 cas :
- je ne savais pas (qu’il fallait fermer la transaction)
- j’ai oublié (qu’il fallait fermer la transaction)
On a probablement tous vécu l’arrêt au 2ème pourquoi: le file system est plein → on supprime les logs et on redémarre l’application. Bien entendu, quelque semaines plus tard, l’application plantera à nouveau pour les mêmes raisons…
Cet exemple souligne l’importance d’aller jusqu’au bout de la démarche pour identifier la cause racine et éradiquer définitivement le problème.
L’étape du PLAN est terminée. Cela peut paraître long mais avec un peu d’entrainement en 10 à 15 min, on peut tout à fait clarifier un problème avec cette démarche.
Etape 2 – DO: Place à l’action !

Maintenant que les causes racines sont identifiées, il ne reste “plus” qu’à trouver des contre-mesures à tester. Ici, on ne parle pas de solutions car on ne sait pas encore si elles vont avoir l’effet attendu.
Le principe est d’identifier quelles contre-mesures à appliquer pour chaque cause racine. Encore une fois, notre cerveau nous joue des tours, et il arrive fréquemment que je voie des contre-mesures qui n’ont aucun rapport avec les causes racines identifiées précédemment: par exemple, un grand classique est d’essayer un outil qui va résoudre le problème à notre place.
Dans notre exemple du serveur qui a planté, on peut en imaginer plusieurs. Si c’est une partie de code particulièrement incidentogène:
- organiser un dojo pour que l’équipe monte en compétences sur cette partie de code
- ajouter des tests automatiques TU / TI pour tester certains cas aux limites
- ajouter des contrôles statiques de code type sonar ou autres
- commenter cette partie du code pour donner des tips pour les futurs dévs
- améliorer la détection / monitoring: quand le file system est à 80% → déplacement auto des logs
- …
La difficulté ici est de vraiment mettre en oeuvre les contre-mesures jusqu’au bout: ne pas lâcher.
Pour cela, le point clé est d’avoir un owner sur chaque contre-mesure et de les mettre en oeuvre le plus vite possible. Le rôle du team leader est essentiel pour s’assurer que l’équipe va jusqu’au bout de ces améliorations et ne se défocalise par sur un autre problème plus récent.
Etape 3 – CHECK: Et ça marche vraiment ?
C’est l’objet de notre prochaine étape: est ce que les contre-mesures ont eu l’effet attendu ? Et c’est à cette étape que le fait de poser le problème initial sous forme d’écart prend tout son sens.
Il y a 2 possibilités:
- soit l’écart n’a pas complètement disparu, la situation s’est améliorée mais on n’est pas encore à l’objectif.
On est sur la bonne voie mais on a probablement raté quelques causes racines ou que les contre-mesures n’ont pas toutes fonctionné comme prévu. Il faut donc faire une nouvelle itération en passant par l’analyse des causes et les idées de contre-mesures.
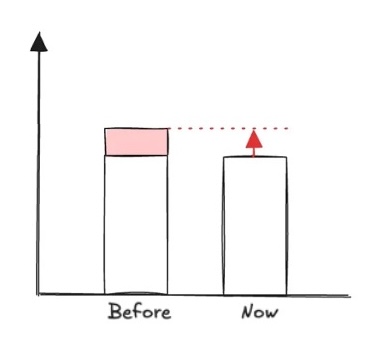
- soit on est à la cible attendue. Bravo, on peut passer à la dernière étape !
Etape 4 – ACT: Qu’est ce qu’on appris au final ?
Il serait dommage de rater cette dernière étape qui consiste à prendre conscience des progrès réalisés et les ancrer en nous profondément.

C’est toute la magie de la résolution de problèmes. Au départ, on la pratique pour résoudre les obstacles et au final, on développe l’expertise des collaborateurs.
Pour ancrer les apprentissages, il faut passer par la reformulation. Parmi mes pratiques ou celles de mon équipe :
- raconter la résolution de problème durant le daily ou à plusieurs collègues,
- la partager durant une réunion de plénière (all hands) devant toute l’équipe,
- organiser un dojo (sorte de mini-formation sur le terrain) pour partager cette nouvelle pratique,
- Ou même écrire un article de blog !
Le fait de raconter en suivant la démarche en 4 étapes permet de prendre conscience du chemin parcouru.
Les pièges à éviter
Quelque travers assez classiques que j’observe sur le terrain:
- Laisser la résolution de problèmes aux experts / team leaders / scrum master La résolution de problèmes est l’affaire de tous, et chaque personne a besoin d’être coachée, idéalement par le team leader.
- Pointer du doigt les personnes qui ont été impliquées dans les causes racines: « C’est Xxxxx qui a planté la production ! ». Les conséquences du fingerpointing sont immédiates: on ne parlera plus des problèmes et une chose est sûre, ils seront là pour longtemps…
- Attendre la fin du sprint, attendre la prochaine rétrospective (le plus classique), attendre la semaine prochaine… Un problème « réchauffé » perd de son impact, plus c’est immédiat, mieux c’est.
- Soyez concis dans la rédaction de votre résolution de problème: pas de longues phrases, des faits sous forme de bullets points extrêmement précis. Idéalement, 1 page A3 ou 2 à 3 pages écran devraient être suffisantes. Cela oblige à un effort de synthèse qui permet aussi d’utiliser votre résolution de problème comme un support de communication pour le partage (lors du Act)
Par où commencer ?
Pour expérimenter cette approche, voici quelque recommandations:
- Commencez par un sujet simple. Comme toute nouvelle pratique, que ce soit la cuisine, le piano, ou la course à pied, il faut commencer par une pièce simple.
- Choisissez un problème à votre portée, c’est à dire sur lequel vous pouvez agir à votre niveau sans avoir besoin d’autres équipes tranverses ni de votre manager.
Ces critères de choix auront pour effet de vous encourager à continuer, soutenu par ces premières réussites. Rien n’est plus satisfaisant et encourageant que de voir les effets de ces premières améliorations qui peuvent paraître anodines mais permettent de mettre le pied à l’étrier.
Dans le prochain article, je vous partage quelques résolutions de problèmes dans le domaine du développement logiciel pour réduire le nombre de bugs lors de rétrospectives agile ainsi que dans le domaine de l’infrastructure pour les incidents.
Et vous, comment aidez vous vos équipes dans la résolution des problèmes du quotidien ? Quelle démarche adoptez vous lorsque vous rencontrez des problèmes de « manager tech » ?
Pour ceux qui préfèrent la vidéo, vous retrouvez cette même démarche ici:
Version courte
Version longue
Laisser un commentaire