
48 jours sans incident sur notre plateforme SaaS. Nous y sommes finalement arrivés.
Mais le chemin depuis 2 ans… Firefighting régulier, task forces, réunions de crise. Et surtout ces moments particulièrement difficiles : un client impacté par un incident qu’on pensait anodin, signalé par les équipes Support via un utilisateur final. Parfois l’escalade, le REX avec le client — présenter ses excuses pour les impacts sur les utilisateurs, expliquer, convaincre que ça ne se reproduira plus.
Pour les équipes, c’est une autre difficulté : interrompus en plein sprint pour éteindre le dernier feu.
Retour sur ces 2 dernières années.
La situation initiale: confusion et firefighting
À mon arrivée en tant que CTO, ma première semaine fut quasiment un bizuthage :
- 2ème jour : incident critique sur 3 serveurs de notre cluster
- 4ème jour : mise en production de la nouvelle version de notre solution SaaS à 21h00 : impossible de redémarrer les serveurs dans de bonnes conditions → Retour arrière. Problème : aucune procédure pour le retour arrière !
- 5ème jour : nouvel incident critique pour les clients.
Après cette première semaine assez éprouvante pour nos utilisateurs et pour nous, j’interroge les équipes tech, les équipes support, les commerciaux…
– C’est toujours comme ça ?
(c’est pas ce qu’on m’avait annoncé pendant l’entretien d’embauche 🙂).
Les retours vont de:
– Oui, c’est compliqué... / Les clients se plaignent de l’instabilité et de ralentissements régulièrement…
à :
– Oh, ça arrive de temps en temps mais globalement ça va, on répare vite.
Au-delà de ces perceptions pour le moins divergentes, j’essaye d’avoir des faits, des mesures… Et là : pas grand chose à part un vieux Google Sheet plus vraiment à jour. Rien d’autre.
Je reviens vers les équipes Ops en charge du maintien en conditions opérationnelles de la plateforme :
– Mais quand il y a un incident, vous notez ce qui se passe, pourquoi c’est arrivé, comment vous avez réparé… ?
– Oui, on essaye mais on a pas toujours le temps.
Bilan: des équipes débordées, pleines de bonne volonté, mais sans boussole. Mon premier réflexe avant de changer quoi que ce soit: Nettoyer la vitre.
Comprendre la situation par des faits et des mesures
Avant de changer quoi que ce soit, je souhaite clarifier la situation. Je me retrouve responsable d’une une solution SaaS instable, avec des impacts clients sérieux — et des équipes qui en paient le prix : stress, context switching, perte de crédibilité en interne… Mais je suis incapable de formaliser le problème. Est-ce que c’est toutes les semaines ? Les incidents sont-ils tous différents, ou y a-t-il de la récurrence selon les jours, les horaires, les saisons ?
Avec l’équipe Ops, nous construisons donc notre Journal des incidents. L’objectif : mesurer et garder une trace de nos apprentissages.
- Les dates de début et de fin de chaque incident → Permettent de mesurer combien d’incidents par jour, par semaine ? Combien de temps on met pour les résoudre ?
- La gravité : quel est l’impact réel pour nos utilisateurs → Permet d’affiner la communication
- La cause racine : pourquoi cet incident est-il arrivé → Permet d’éradiquer définitivement plutôt que mettre un pansement.
- Les contre-mesures immédiates : comment on répare aussi vite que possible.
- Les contre-mesures à froid et leur vérification : s’assurer du progrès sur la durée
(Plus d’info sur cette démarche de résolution de problème, ici: Transformer les problèmes en apprentissages)
Pour ce faire, un simple tableau dans Notion :
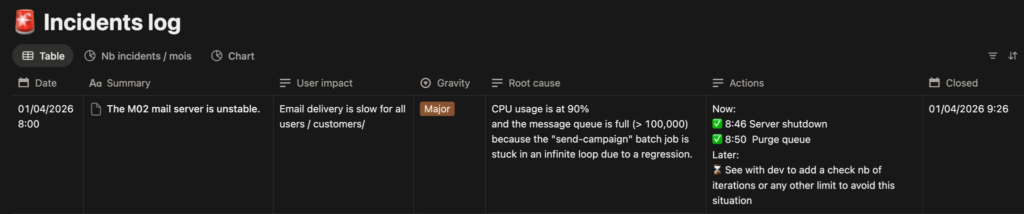
Et derrière chaque ligne qui résume l’incident, il y a une page complète avec l’analyse détaillée, des copies d’écrans, des extraits de logs, les heures précises de chacune des contremesures…
Voici un extrait d’une analyse plus complète:
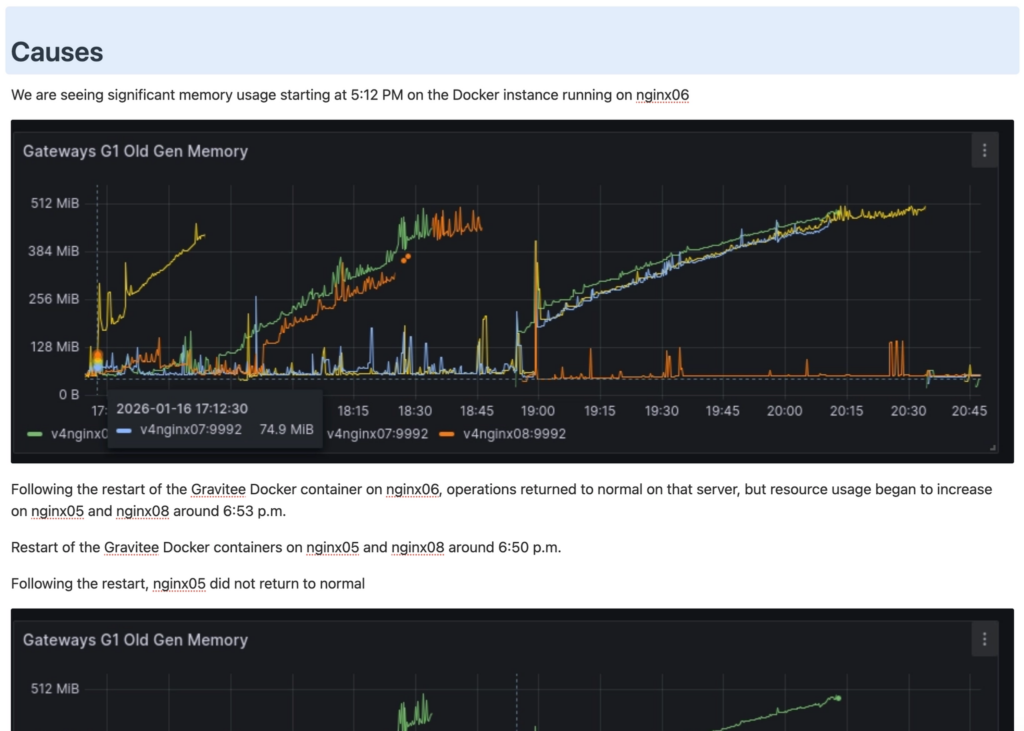
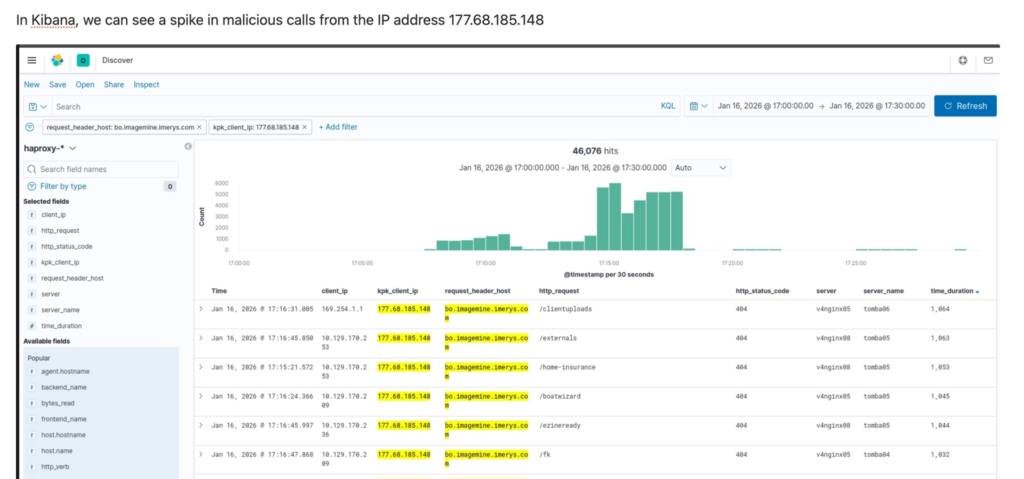
Ce journal devient notre boussole. Et très vite, les chiffres parlent d’eux-mêmes : combien d’incidents par semaine, leur récurrence (« Mais celui-là, c’est la 5ème fois ce mois — et on n’a toujours pas cracké la cause racine ! »). Leur impact réel pour les équipes: « On passe entre 1 et 2 jours par semaine à réparer. », » « On est dérangé 1 week-end sur 2… pour rien. Et ces faux positifs, il faudrait vraiment s’en occuper ». L’équipe et moi prenons conscience de l’ampleur du problème. Mais cette fois, on peut le mesurer et le formaliser. On sait de quoi on parle.
De plus, au niveau du Comité de Direction, voici les 3 indicateurs de stabilité de la plateforme que je partage chaque semaine:
- Nombre d’incidents de la semaine : toutes gravités confondue → Cible = 1 max
- Nb de hot-patchs : correctifs appliqués sur une livraison pour résoudre un bug non détecté → Cible = 0
- Nb de rollback sur les mises en production: échec du déploiement d’une nouvelle version et retour à la version précédente → Cible = 0
Maintenant que la situation est clarifiée et factualisée, voyons comment l’améliorer.
Construire nos standards de travail pour être efficace
Au début, on se rend compte que l’improvisation est la norme. Pas de démarche structurée pour analyser la cause racine, pas de consensus sur la gravité, une communication interne et externe qui prend un temps infini à rédiger selon l’inspiration du moment…
On se met donc d’accord sur des standards de travail (un standard de travail correspond à la meilleure façon connue de réaliser une tâche).
Les niveaux de gravité
Initialement, entre nos SLA client, les niveaux de gravité dans nos tickets de support client (Zendesk chez nous), et les gravités dans les tickets Tech (Jira), il n’y a pas de cohérence. Chacun a son avis, son échelle de valeur.
En quelque semaines, on arrive à un consensus sur 3 niveaux pour en interne : simple mais efficace. Pour 90% des tickets, ça fonctionne bien même s’il reste toujours quelques cas à la marge où on hésite entre Majeur et Critique.

Définir la gravité, c’est bien, savoir comment communiquer en conséquence, c’est autre chose. On a donc également standardisé nos communications.
Les templates de communication
En interne d’abord, via Slack : un message structuré, envoyé dès le début de l’incident, qui donne à toutes les équipes (Ops, Support, CSM, top management…) la même information au même moment.

En externe ensuite, à destination de nos clients. On a travaillé des templates par type de scénario :
- Erreur humaine / erreur de déploiement
- Bug applicatif critique
- Pic de charge / surcharge des serveurs
- …
Eviter de partir d’une page blanche quand on est sous stress. Le fond est déjà prêt, il ne reste qu’à adapter les détails.
Exemple d’un template de mail:
Dear user,
We are writing to inform you that [Your platform name] was temporarily unavailable following an error that occurred during a maintenance / deployment operation.
The issue has been identified and resolved by our teams. The service has now been fully restored and is operating normally. We are implementing a specific reinforced monitoring measure to prevent this from recurring in the future.
We would like to sincerely apologise for this unexpected service interruption and any inconvenience it may have caused.
The Tech Team
Et nous arrivons au coeur de l’incident, la recherche de cause racine.
La recherche de cause(s) racine
Nous avons construit une checklist de départ des outils d’investigation ainsi que quelque schémas de flux et d’architectures. L’objectif est d’accélérer la résolution quelque soit les personnes qui sont mobilisées. La checklist couvre les changements récents dans notre infra, les logs à consulter, les dashboards de monitoring essentiels, et une base de données de FAQ des incidents passés pour chercher des similitudes:
Extrait:
[ ] What has changed since the incident? Claranet? Azure? Platform.sh?
[ ] Kibana HA Proxy / Logs Refront / Logs NGINX sur restore
[ ] Prometheus / Grafana: servers, DB, ES, NetApp
[ ] Dashboard Azure
[ ] Search for similar incidents in this database: Incident Concept
[ ] FAQ on this type of incident
[ ] …
C’est sans aucun doute la partie la plus difficile. J’essaye d’encourager le pattern suivant: brainstormer sur plusieurs hypothèses, assigner chaque hypothèse à une personne afin qu’il puisse la confimer ou pas, et itérer jusqu’à identifier la ou les causes racines.
Un point chaque matin pour organiser la journée de l’équipe
Et dernier standard de travail, pour mettre l’équipe en mouvement et s’assurer d’aller jusqu’au bout des contremesures à froid, l’équipe Ops a son daily meeting, tout comme les équipes de développement.
Voici notre standard – 20min chaque matin à partir de 9h10:
Qui est disponible aujourd’hui pour la gestion des incidents ? Qui est absent ?
→ S’assurer de la couverture complète de supervision de 8h30 à 18h00
Revue des incidents
→ Retour sur les actions à froid: quelles sont les contremesures à finaliser
Astreinte de la nuit
→ Y a t il eu un appel ? Faut il revoir un faux positif ?
Revue des opérations prévues dans la journée sur la plateforme
→ Rappel pour l’équipe, s’assurer que tout est prêt.
Les projets sur le long cours (migration, sécurité…)
→ Y a t il des blocages, des avancés ?
Tour de table individuel
→ Qu’est ce qui est prévu pour chacun aujourd’hui, qui a besoin d’aide…
Le plus difficile pour les équipes
Ecrire pour prendre du recul
Au départ, les équipes prennent tous ces changements pour de la bureaucratie et une perte de temps :
– Il va falloir écrire tout ça ? Et à quoi ça sert d’écrire de noter une action si elle n’a pas marché ?
Effectivement, cela prend quelques minutes de rédiger. Mais c’est aussi l’occasion de prendre un tout petit peu de recul sur la situation :
– Mais il a commencé quand vraiment l’incident ? À 11h23 quand j’ai lu le mail d’alerte ou à 8h30 quand nos utilisateurs ont démarré leur journée ?
Et enfin, on construit notre base de connaissance :
– Mais cet incident, il ne serait pas déjà arrivé ?
Et ce point s’avère encore plus essentiel pour entrainer les IA (cf. prochaines étapes ci-dessous).
Les racines du mal
Mais le plus difficile reste d’identifier la (les) vraie(s) cause(s) racine.
Prenons un exemple d’incident : « La fonction d’envoi de mails en masse ne fonctionne plus ». Pourquoi ?
– Parce que Le scheduler d’envoi de mail est tombé → Pas la cause racine
– Parce qu’il a fait un out of memory → Pas la cause racine
– Parce qu’on a introduit un retry qui ne tient plus compte du Nb Tentatives Max = 5 depuis la version 4.6.2, ce qui crée une boucle infinie et un Out of memory → Bingo, c’est la cause racine.
Au début, l’équipe s’arrête souvent à une cause apparente de 1er ou 2ème niveau. Et il faudra des semaines voire plus pour que l’ensemble de l’équipe arrive à qualifier correctement un incident sans mélanger: symptôme visible, impact pour les utilisateurs, et cause racine. C’est tout à fait normal, c’est une mécanique qui parait simple de prime abord mais qui ne l’est pas.
Choisir ses combats
En tant que manager ou CTO, on voudrait se battre sur chaque incident mais il faut aussi parfois accepter de lâcher : quand les équipes sont déjà mobilisées sur plusieurs chantiers lourds, ou quand la probabilité de récurrence est trop faible pour justifier l’investissement. C’est un choix, pas un renoncement.
Parfois aussi, on sera juste incapable de l’identifier : parce qu’on manque de logs, parce qu’on a oublié de faire un thread dump…
Au final, ce qui est encourageant, c’est que petit à petit, l’habitude se prend. Il n’est plus nécessaire de vérifier à chaque fois si l’incident a été tracé, si la communication a bien été faite… Et une habitude, c’est un peu comme se laver les dents : au début c’est compliqué et ennuyeux, et après quelques mois on ne s’en rend même plus compte. Et puis les premières résolutions d’incident portent leurs fruits, le nombre d’incident diminue implacablement. Ces résultats sont autant d’encouragement pour continuer à améliorer nos pratiques.
Avoir les bons réflexes face à un incident, c’est bien. Mais quand ça s’emballe — plusieurs alertes en parallèle, des équipes débordées, des clients qui appellent — il faut autre chose : un process clair pour garder la tête froide et coordonner efficacement. C’est ce qu’on a construit ensuite.
Rester sereins même quand il y a le feu: le process nous guide
Avant qu’on structure tout ça, un incident critique ressemblait souvent à : des conversations sur Slack en parallèle, le support qui appelle les Ops, une pluie de question pour savoir où on est , si “ça avance”… Le firefighting.
L’objectif de notre process : que chacun sache exactement quoi faire, apporter une forme de sérénité dans l’action afin que nos cerveaux restent concentrés sur la résolution. Et que les autres équipes — le CEO, le support, les CSM — soient rassurées sur la prise en charge.
Voici notre process simplifié de bout en bout :
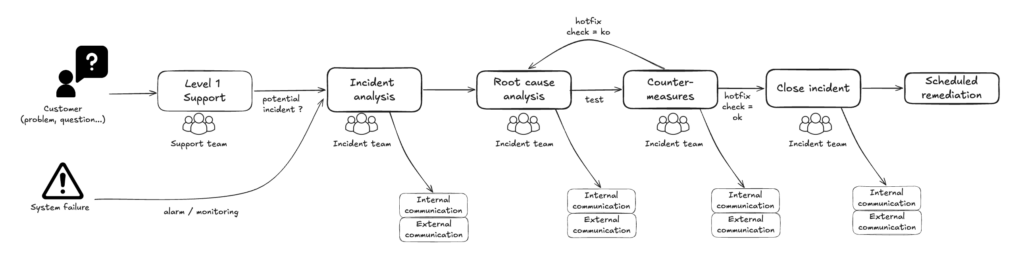
Mobiliser et communiquer: Analyse de l’Incident
Un incident remonte depuis un client, depuis une sonde, ou via une personne en interne. Le pilote de l’incident est immédiatement nommé. Il est chargé de :
- s’assurer que l’équipe est mobilisée autour d’un canal video
- ouvrir l’incident: la page Notion est crée et tout y est loggué
- communiquer dans le canal Slack #incident toutes les 20 à 30 min voire de proposer une communication en externe en fonction de la gravité.
Résultat : toute personne dans l’entreprise est informée en temps réel, de l’apparition jusqu’à la résolution. Inutile que chacun aille à la pêche aux infos. Nos collègues savent que les équipes tech sont sur le coup et qu’elles les tiennent informés — ça crée de la confiance.
Recherche de causes racine et Contre-mesures
Les experts techniques mobilisés étudient les hypothèses de causes, les vérifient sur le terrain, confrontent leurs idées à travers le canal dédié. Les premières contre-mesures sont testées.
Le pilote d’incident n’est pas la pour résoudre mais il s’assure que toutes les pistes sont bien étudiées, et communique en temps réel sur l’avancement de la résolution. Il protège aussi l’équipe des sollicitations extérieures.
Clôture de l’incident
Le pilote d’incident communique la bonne nouvelle et s’assure que les prochaines étapes (Scheduled Remediation) ont bien toute chacun un responsable et une date: préparation d’un correctif définitif, une action de remédiation sur les serveurs… Il s’assure que la page de l’incident est bien claire et à jour.
Retour à nos activités normales.
Quand c’est vraiment critique
Quand un incident s’avère critique pour nos utilisateurs, un process d’escalade se déclenche pour mobiliser immédiatement toute l’équipe nécessaire :
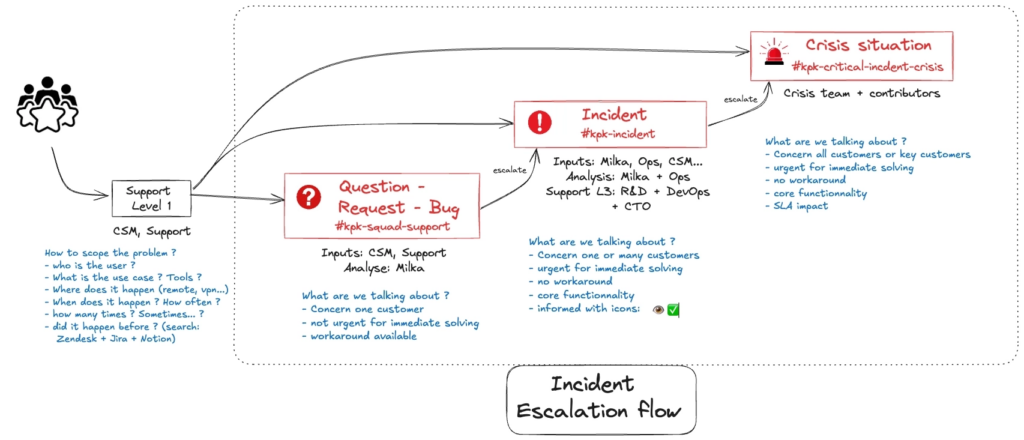
Mon smartphone se met à sonner ainsi que celui d’autres managers identifiés. A ce moment là, j’arrête tout ce que je fais et je rejoins le canal vidéo ouvert spécialement pour la crise pour prendre le pilotage de l’incident. Une fois l’équipe mobilisée, le process est le même que pour un incident mineur ou majeur — la différence, c’est la vitesse et le niveau d’escalade.
Nos prochaines étapes
Tout d’abord, nous avons créé notre IA RAG nourrie de plus de 400 incidents patiemment étudiés dans notre Journal ainsi que des échanges dans nos différents canaux Slack. Ce corpus de données propres nous permet d’utiliser l’IA pour :
- nous aider à résoudre les incidents plus vite,
- identifier les récurrences: quels sont les incidents les plus fréquents sur telle partie de l’infra…
- anticiper les futurs défaillances: quels sont les problèmes qui semblent lier à certaines périodes de l’année, aux débuts / fins de mois…
(plus d’infos ici sur l’IA RAG dopée aux données terrain)
Et pour lutter contre la “dette cognitive” (un peu comme le pompier qui ne sait plus éteindre les incendies s’il n’a l’occasion de pratiquer), nous avons décidé de simuler des incidents à blanc pour éviter de nous rouiller.
Pour terminer cet article, notre prochaine étape — encore au stade de prototype —, c’est l’Agentic: déployer des agents autonomes pour superviser et réagir aux alertes. En croisant les notifications Sentry, les alertes Grafana et les différents logs…, un agent peut alors identifier si une solution éprouvée existe qui sera proposée à un Ops. L’humain reste au coeur du process.
Grand merci à Xavier, Benjamin, Pierre, Titouan et Bénédicte principaux contributeurs de ce chantier, à Thomas notre CEO pour sa confiance et enfin à nos clients pour leur patience 🙏
Laisser un commentaire